

우하하 우수혼공족 됐다 ㅎㅅㅎ
앞으로 더 열심히 해야지 ><
+ 복습할 때 깨달았는데, 코드가 안 쓰여있어서 복습할 때 꽤 애썼다..ㅜ
이번에는 코드를 하나하나 넣어봐야겠땅😄
Chapter 3 : 회귀 알고리즘과 모델 규제
3-1 k-최근접 이웃 회귀
회귀(regression) ? 클래스 중 하나로 분류하는 것이 아닌, 임의의 어떤 숫자를 예측하는 문제
ex) 내년도 경제 성장률 예측, 배달 도착 시간 예측, 농어의 무게 예측
- 정해진 클래스가 없고 임의의 수치를 출력함
- 두 변수 사이의 상관관계를 분석하는 방법
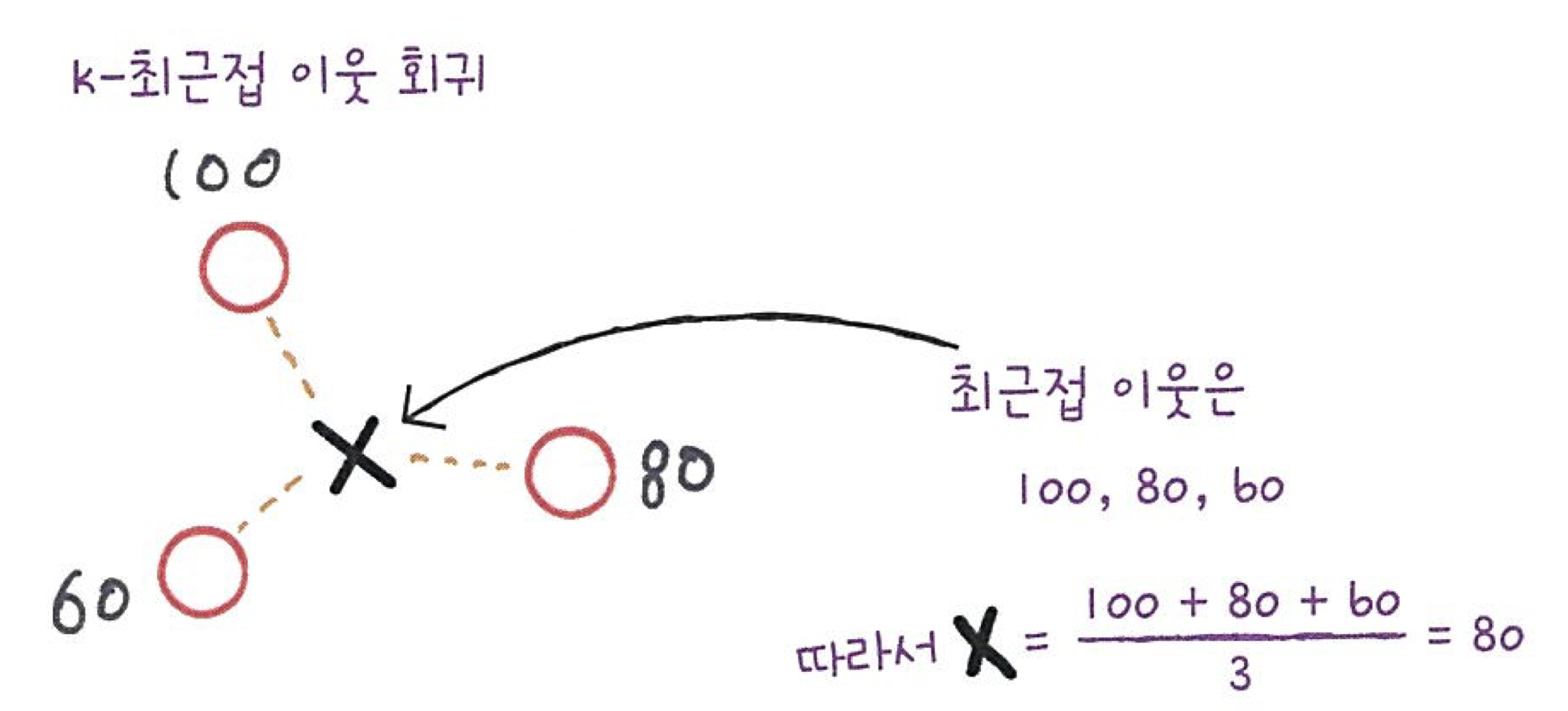
<K-최근접 이웃 회귀>
- K-최근접 이웃 분류 알고리즘
1. 예측하려는 샘플에 가장 가까운 샘플 k개 선택
2. 샘플들의 클래스 확인, 다수 클래스를 새로운 샘플의 클래스로 예측

- K-최근접 이웃 회귀 알고리즘
1. 예측하려는 샘플에 가장 가까운 샘플 k개 선택
* 여기서 이웃 샘플의 타깃은 클래스가 아닌 임의의 수치
2. 이웃 샘플의 수치 확인
3. 수치들의 평균 구하기
- 데이터 준비 및 모델 만들기
import numpy as np
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])import matplotlib.pyplot as plt
plt.scatter(perch_length, perch_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight, random_state=42)
# 2차원 배열로 바꾸기
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
print(train_input.shape, test_input.shape)
<몰랐던 것 + 복습>
- 사이킷런에 사용할 훈련 세트는 2차원 배열이므로, 2차원 배열로 바꿔주기
- 1차원 배열의 크기는 원소가 1개인 튜플로 만듦 -> 단순 1차원 배열이면 shape을 출력했을 때 (n, )로 출력
- 2차원 배열로 바꿈 -> 억지로 하나의 열 추가 -> 2차원 배열이면 (n, 1)로 출력됨
- 여러 개의 열로 만들고 싶으면, reshape(n, m) 사용
- n = -1 -> 나머지 원소 개수로 모두 채움

<결정계수(R^2)>
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
# K-최근접 이웃 회귀 모델을 훈련함
knr.fit(train_input, train_target)
print(knr.score(test_input, test_target))print(knr.score(test_input, test_target))해당 코드를 실행하면 0.9928094061010639 라는 점수 출력
-> 결정계수(coefficient of determination)
- 결정계수 계산 방법
- 예측에 가까워질수록 1에 가까워- 예측에 가까워질수록 1에 가까워짐
- 타깃의 평균 정도를 예측하는 수준일수록 0에 가까워짐

from sklearn.metrics import mean_absolute_error # 타깃과 예측의 절댓값 오차를 평균하여 반환
# 테스트 세트에 대한 예측 만듦
test_prediction = knr.predict(test_input)
# 테스트 세트에 대한 평균 절댓값 오차 계산
mae = mean_absolute_error(test_target, test_prediction)
print(mae) # 출력 : 19.157142857142862 -> 예측이 평균적으로 19g 정도 타깃값과 다르다는 뜻<과대적합 vs 과소적합>
- 과대적합(overfitting) ? 훈련 세트에서 점수가 굉장히 높으나, 테스트 세트에서는 점수가 굉장히 낮을 때
- 훈련 세트에만 잘 맞는 모델이 됨 - 과소적합(underfitting) ? 훈련 세트보다 테스트 세트에서 점수가 굉장히 높거나, 두 세트에서의 점수가 모두 낮을 때
- 모델이 너무 단순하거나, 데이터 세트가 너무 적을 때 발생
2주차 기본 숙제 : Ch.03(03-1) 2번 문제 출력 그래프 인증하기
2. 과대적합과 과소적합에 대한 이해를 돕기 위해 복잡한 모델과 단순한 모델을 만들겠습니다. 앞서 만든 k-최근접 이웃 회귀 모델의 k값을 1, 5, 10으로 바꿔가며 훈련해 보세요. 그 다음 농어의 길이를 5에서 45까지 바꿔가며 예측을 만들어 그래프로 나타내 보세요. n이 커짐에 따라 모델이 단순해지는 것을 볼 수 있나요?
knr = KNeighborsRegressor()
# 5~45까지 x 좌표를 만듦
x = np.arange(5, 45).reshape(-1, 1)
for n in [1, 5, 10]:
knr.n_neighbors = n
knr.fit(train_input, train_target)
# 지정한 범위 x에 대한 예측 구하기
prediction = knr.predict(x)
# 훈련 세트와 예측 결과를 그래프로 그리기
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.show() n_neighbors = 1 |
 n_neighbors = 5 |
 n_neighbors = 10 |
3-2 선형 회귀
<K-최근접 이웃의 한계>
: 새로운 샘플이 훈련 세트의 범위를 벗어나면 엉뚱한 값을 예측할 수 있음
# 50cm 농어의 무게 예측
print(knr.predict([[50]])) # 1033.33333333
import matplotlib.pyplot as plt
# 50cm 농어의 이웃
distances, indexes = knr.kneighbors([[50]])
# 훈련 세트의 산점도 그림
plt.scatter(train_input, train_target)
# 이웃 샘플만 그림
plt.scatter(train_input[indexes], train_target[indexes], marker='D')
plt.scatter(50, 1033, marker='^')
plt.show()
print(np.mean(train_target[indexes])) # 1033.33333333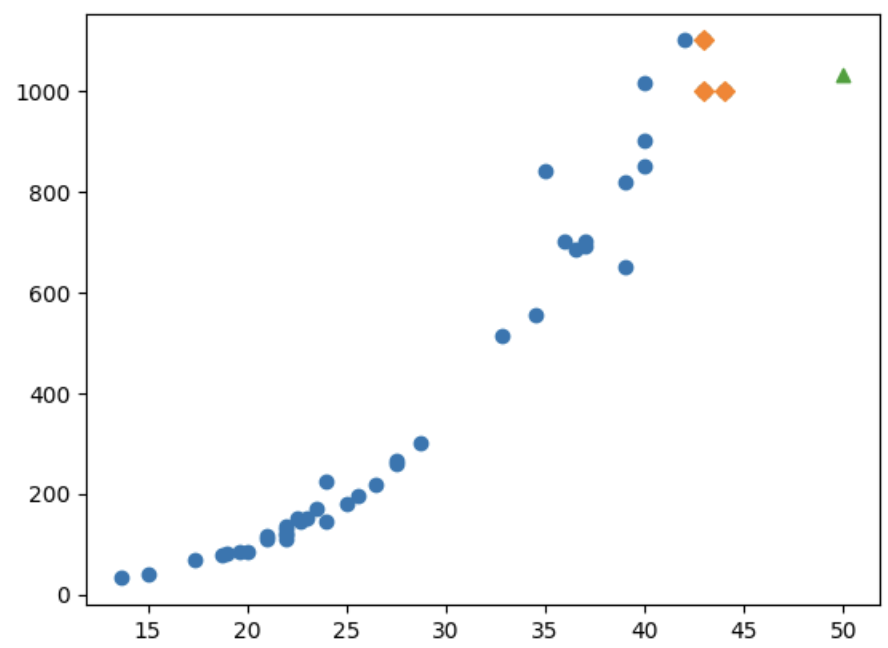
<선형 회귀>
선형 회귀(linear regression) ? 특성이 하나인 경우 어떤 직선을 학습하는 회귀 알고리즘
- 어떤 직선이라 하믄 그 특성을 가장 잘 나타낼 수 있는 직선

- 사이킷런 : sklearn.linear_model 패키지 아래에 잇는 LinearRegression 클래스로 선형 회귀 알고리즘을 구현!
- lr.coef_ : y = ax + b 에서의 a
- lr.intercept_ : y = ax + b 에서의 b
-> coef_, intercept_를 머신러닝 알고리즘이 찾은 값이라는 의미에서 모델 파라미터(model parameter)라고 부름 - 모델 기반 학습 ? 최적의 모델 파라미터를 찾는 훈련 과정
- 사례 기반 학습 ? 모델 파라미터가 없으며, 훈련 세트를 저장하는 것만 있는 훈련 과정
2주차 추가 숙제 : 모델 파라미터에 대해 설명하기
모델 파라미터(model parameter) ? 선형 회귀 모델이 찾은 방정식의 계수
ex) 선형 회귀 모델에서의 가중치, 절편 / 인공 신경망에서의 가중치, 편향
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_input, train_target)
print(lr.predict([[50]])) # 1241.83860323k-최근접 이웃 회귀보다 무게를 더 높게 예측함
plt.scatter(train_input, train_target)
# 15~50까지 일차방정식 그래프 그림
plt.plot([15, 50], [15*lr.coef_ + lr.intercept_, 50*lr.coef_ + lr.intercept_])
plt.scatter(50, 1241.8, marker='^')
plt.show()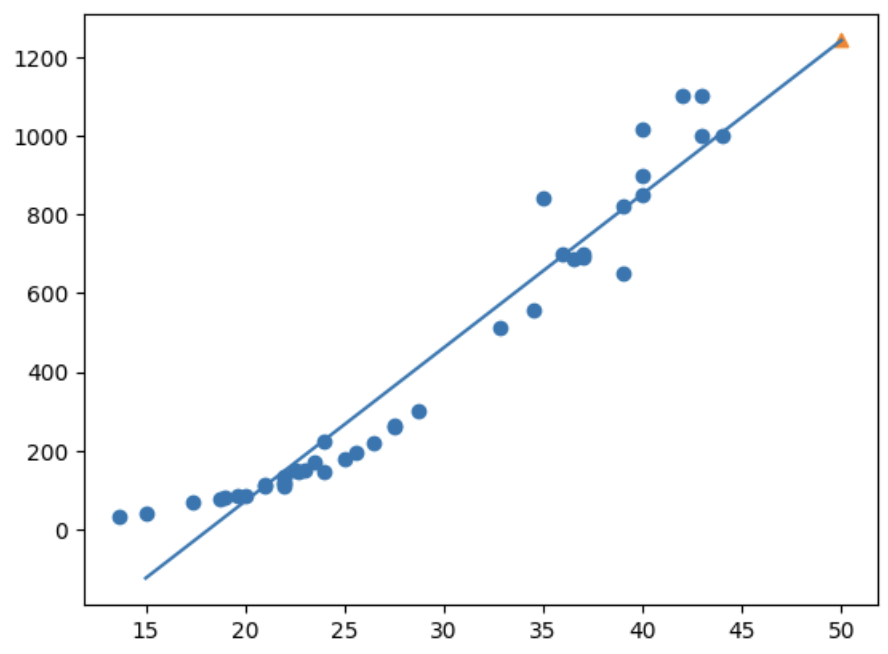
예측값이 직선 위에 위치해 있음!!! -> 훈련 세트 범위 외의 농어의 무게를 예측할 수 있게 됨!!!!! 끼얏호~!
<다항 회귀>
다항 회귀(polynomial regression) ? 다항식을 사용한 선형 회귀
최적의 직선이 아닌 최적의 곡선을 찾음
train_poly = np.column_stack((train_input ** 2, train_input))
test_poly = np.column_stack((test_input ** 2, test_input))
print(train_poly.shape, test_poly.shape) # (42, 2) (14, 2)
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.predict([[50**2, 50]])) # [1573.98423528]point = np.arange(15, 50)
plt.scatter(train_input, train_target)
# 15~50까지 일차방정식 그래프 그림
plt.plot(point, 1.01*point**2 - 21.6*point + 116.05)
plt.scatter([50], [1574], marker='^')
plt.show()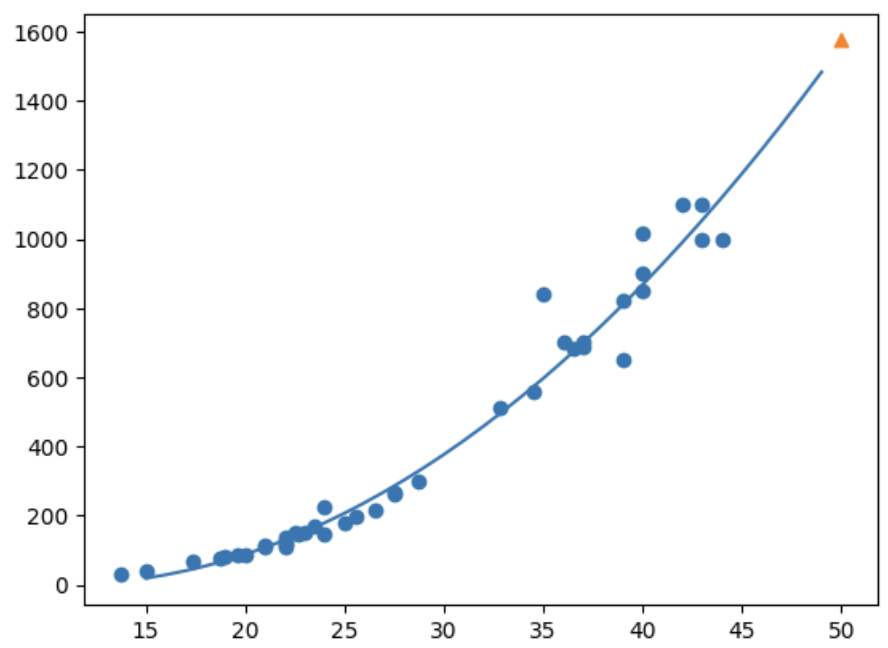
선형 회귀에서 나온 그래프보다 정확성이 더 높음
3-3 특성 공학과 규제
<다중 회귀>
다중 회귀(multiple regression) ? 여러 개의 특성을 사용한 선형 회귀

특성 공학(feature engineering) ? 기존의 특성을 사용해 새로운 특성을 뽑아내는 작업
ex) 농어의 길이, 높이, 두께라는 특성을 각각 제곱하여 추가, 거기에 각 특성을 서로 곱해서 또 다른 특성을 만들어냄
<데이터 준비>
판다스(pandas) ? 데이터 분석 라이브러리
데이터프레임(dataframe) ? 판다스의 핵심 데이터 구조
- 넘파이 배열과 비슷하지만 더 많은 기능을 제공하며, 넘파일 배열로 쉽게 바꿀 수 있음
- 보통 CSV파일을 사용하여 데이터프레임을 만듦
- pd.read_csv() 을 사용하여 CSV 파일을 읽음
- to_numpy() 을 사용하여 넘파일 배열로 바꿈
import pandas as pd
df = pd.read_csv('https://bit.ly/perch_csv')
perch_full = df.to_numpy()
print(perch_full)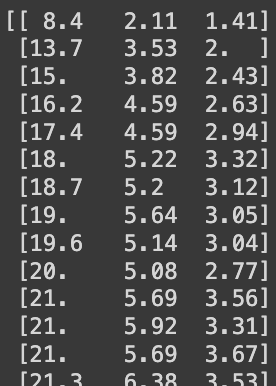
import numpy as np
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_full, perch_weight, random_state=42)<사이킷런의 변환기>
변환기(transformer) ? 특성을 만들거나 전처리하는 클래스 ( <-> 모델 클래스 : 추정기(estimator))
- 입력 데이터를 변환하는 데 타깃 데이터가 필요하지 않음
- 변환기 클래스는 모두 fit(), transform() 메서드 제공
- fit() : 새롭게 만들 특성 조합을 찾음
- transform() : 실제로 데이터를 변환
- 여기서 사용하는 변환기 클래스 : PolynomialFeatures
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures()
poly.fit([[2, 3]]) # 2개의 특성 2와 3으로 이루어진 샘플 사용
print(poly.transform([[2, 3]])) # [1. 2. 3. 4. 6. 9.]2개의 특성을 가진 샘플 [2, 3] -> 6개의 특성을 가진 샘플 [1. 2. 3. 4. 6. 9.]로 변환됨
[2, 3] -> [1. 2. 3. 4. 6. 9.] 변환!
값이 이렇게 나온 이유는,
PolynomialFeatures 클래스는 기본적으로 각 특성을 제곱한 항을 추가하고 특성끼리 서로 곱한 항을 추가함
=> 기존 2, 3, 2*2 = 4, 2*3 = 6, 3*3 = 9, 1
여기서 1이 생긴 이유는? 무게 = a * 길이 + b * 높이 + c * 두께 + d + 1 <- 자동으로 절편인 1이 추가됨
근데 사이킷런의 선형 모델은 자동으로 절편 추가하므로 굳이 1 필요 X -> include_bias=False 사용
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(include_bias=False)
poly.fit([[2, 3]])
print(poly.transform([[2, 3]])) # [2. 3. 4. 6. 9]poly = PolynomialFeatures(include_bias=False)
poly.fit(train_input)
train_poly = poly.transform(train_input)
print(train_poly.shape) # (42, 9) <- 9개의 특성이 만들어짐- get_feature_names_out() : 여러 개의 특성이 각각 어떤 입력의 조합으로 만들어졌는지 알려줌
* 교재에는 get_feature_names()로 나와있다. 그러나, 파이썬의 버전이 업데이트되면서 get_feature_names_out()이 위의 역할을 하게 되었다!*
poly.get_feature_names_out()
# array(['x0', 'x1', 'x2', 'x0^2', 'x0 x1', 'x0 x2', 'x1^2', 'x1 x2','x2^2'], dtype=object)# 테스트 세트 변환
test_poly = poly.transform(test_input)<다중 회귀 모델 훈련하기>
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target)) # 0.9903183436982125
print(lr.score(test_poly, test_target)) # 0.9714559911594111특성이 늘어날수록 정확도 증가! & 과소적합 없어짐
degree ? 필요한 고차항의 최대 차수를 지정하는 PolynomialFeatures 클래스에 내장되어있는 매개변수,
poly = PolynomialFeatures(degree=5, include_bias=False)
poly.fit(train_input)
train_poly = poly.transform(train_input)
test_poly = poly.transform(test_input)
print(train_poly.shape) # (42, 55)특성이 55개나 만들어짐!!
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target)) # 0.9999999999996433
print(lr.score(test_poly, test_target)) # -144.40579436844948테스트 세트 점수 주목 -> 훈련 세트의 정확도만 엄청 높은 과대적합 발생
=> 특성의 개수를 조절하는 것이 중요!!
<규제>
규제(regularization) ? 머신러닝 모델이 훈련 세트에 과대적합되지 않도록 만드는 일
- 선형 회귀 모델의 경우, 특성에 곱해지는 계수(or 기울기)의 크기를 작게 만듦

** 규제를 적용하기 전 정규화 진행
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_poly)
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)<릿지 회귀>
- 선형 회귀 모델에 규제를 추가한 모델, 릿지와 라쏘
- 릿지(ridge) ? 계수를 제곱한 값을 기준으로 규제 적용, 보통 많이 씀
- 라쏘(lasso) ? 계수의 절댓값을 기준으로 규제 적용
from sklearn.linear_model import Ridge
ridge = Ridge()
ridge.fit(train_scaled, train_target)
print(ridge.score(train_scaled, train_target)) # 0.9896101671037343
print(ridge.score(test_scaled, test_target)) # 0.9790693977615387과대적합 없어짐 -> 테스트 세트에서도 좋은 성능 나타냄
하이퍼파라미터(hyperparameter) ? 머신러닝 모델이 학습할 수 없고 사람이 알려줘야 하는 파라미터
- 릿지와 라쏘 모델을 사용할 때 , alpha 매개변수를 사용하여 규제의 강도 조절
- alpha 큼 -> 규제 강도 세짐 -> 과소적합되도록 유도
- alpha 작음 -> 규제 강도 약해짐 -> 과대적합되도록 유도
import matplotlib.pyplot as plt
# alpha 값을 바꿀 때마다, score() 메서드의 결과를 저장할 리스트
train_score = []
test_score = []
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
ridge = Ridge(alpha=alpha)
ridge.fit(train_scaled, train_target)
train_score.append(ridge.score(train_scaled, train_target))
test_score.append(ridge.score(test_scaled, test_target))
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.show()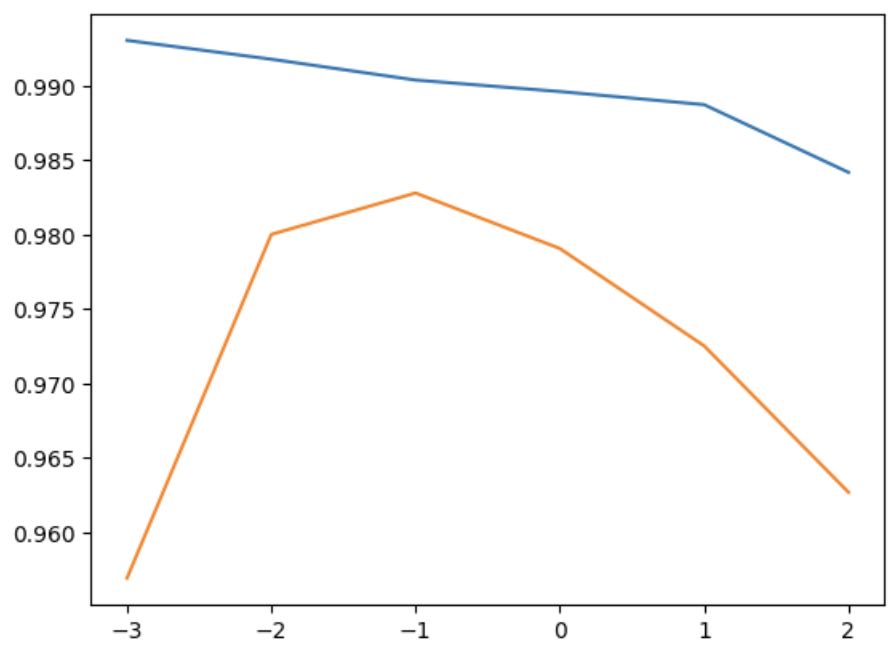
왼쪽으로 갈수록 과대적합에 가까워지고, 오른쪽으로 갈수록 과소적합에 가까워짐
=> 좋은 성능을 가지기 위한 alpha의 값은 대략 0.1임
<라쏘 회귀>
실행 방법은 릿지와 별반 다른 게 없음
from sklearn.linear_model import Lasso
lasso = Lasso()
lasso.fit(train_scaled, train_target)
print(lasso.score(train_scaled, train_target)) # 0.989789897208096
print(lasso.score(test_scaled, test_target)) # 0.9800593698421883# alpha 값을 바꿀 때마다, score() 메서드의 결과를 저장할 리스트
train_score = []
test_score = []
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
lasso = Lasso(alpha=alpha, max_iter=10000)
lasso.fit(train_scaled, train_target)
train_score.append(lasso.score(train_scaled, train_target))
test_score.append(lasso.score(test_scaled, test_target))
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.show()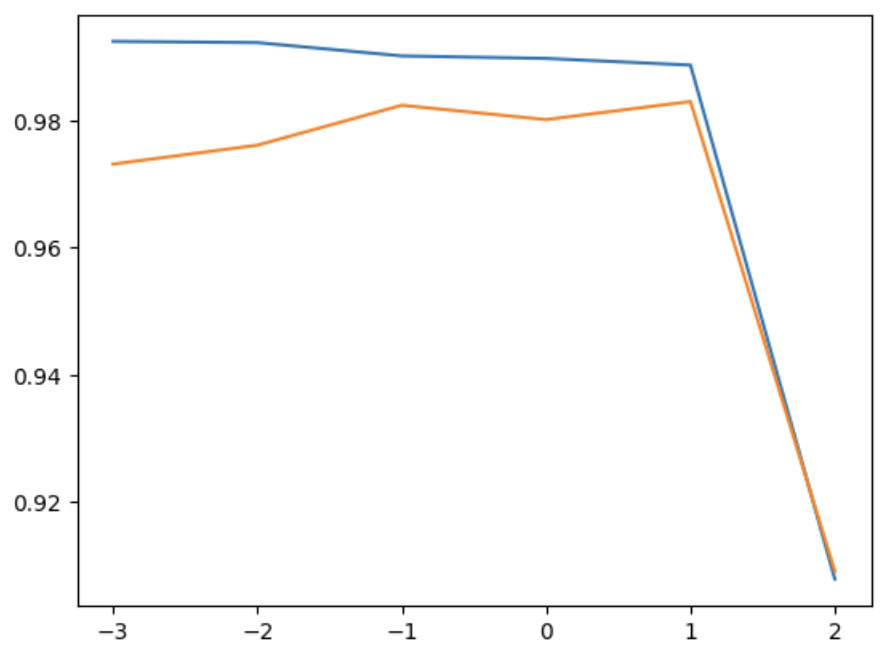
릿지와 마찬가지로 왼쪽으로 갈수록 과대적합에, 오른쪽으로 갈수록 과소적합에 가까워지는 것을 알 수 있음
=> 좋은 성능을 가지기 위한 alpha의 값은 대략 1임
lasso = Lasso(alpha=0.1)
lasso.fit(train_scaled, train_target)
print(lasso.score(train_scaled, train_target)) # 0.9888067471131867
print(lasso.score(test_scaled, test_target)) # 0.98244705987066952주차를 마치며..
챕터3에 들어오니 본격적인 머신러닝을 배우는 것 같다는 기분이 들었다. 그만큼 어려웠다는 뜻..ㅜ
생소한 용어들이 특히 이번 챕터에 많이 나온 듯하다. 예를 들면, 회귀라던가... 릿지, 라쏘 등등..
그래도 코딩을 해보면서 저번 챕터에서 배웠던 것들이 새록새록 기억나는 게 왕신기했다 :)
이것이 복습의 맛인가.. 언제나 새로워 최고야 짜릿해
챕터4에서는 드디어 (말로만) 많이 들어봤던 로지스틱 회귀가 나온다!!
기대되기도 하면서 어려울 듯해서 긴장도 된다 ㅎㅅㅎ
아직까지는 그래도 할 만해서 다행이다 야호야호~!~ 다음 챕터도 기대된다 🤩
'혼공머신' 카테고리의 다른 글
| [혼공머신] 6주차 : ch7) 딥러닝을 시작합니다 (0) | 2024.08.18 |
|---|---|
| [혼공머신] 5주차 : ch6) 비지도 학습 (0) | 2024.08.11 |
| [혼공머신] 4주차 : ch5) 트리 알고리즘 (0) | 2024.07.28 |
| [혼공머신] 3주차 : ch4 (0) | 2024.07.21 |
| [혼공머신] 1주차 : ch1, ch2 (0) | 2024.07.06 |