
본격적으로 들어가기 전, 왜 머신러닝에 대해 공부하게 되었는가?
요즘 트렌드가 AI인 것은 모두가 다 아는 사실, 근데 난 AI에 대해 아는 게 거의 없다.. 거의 개념이랑 종류만 아는 정도..?
명색이 컴공인데 인공지능 모르는 게 말이 되냐며.. 약간 부끄럽기도 했다 ㅜ
그래서 인공지능을 공부하기로 마음 먹었따! 우하하
인공지능을 공부할 때, 가장 접근하기 쉬운 과목이 머신러닝이라고 해서, 이왕 공부할 거 하나하나 차근차근 공부해보고 싶었다.
또한 마침 혼공학습단 신청을 시작했길래, 진짜 열심히 해보자는 마인드로 바로 신청했다 :) 진짜 열심히 해야쥐 야호~!
Chapter 1 : 나의 첫 머신러닝
1-1 인공지능과 머신러닝, 딥러닝
인공지능(Artificial intelligence) ? 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템
- 강인공지능 (Strong AI) : 사람과 구분하기 어려운 지능을 가진 컴퓨터 시스템 (like 터미네이터)
- 약인공지능 (Weak AI) : 특정 분야에서 사람의 일을 도와주는 보조 역할만 가능한 컴퓨터 시스템 (like 알파고, 클로바, 시리)
머신러닝(Machine Learning) ? 규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 지능을 구현하기 위한 SW 담당
- 통계학과 관련됨
- 대표적인 머신러닝 라이브러리 : 사이킷런(scikit-learn)
딥러닝(Deep Learning) ? 인공 신경망(artificial neural network)을 기반으로 한 방법들을 통칭하여 부르는 인공지능 분야
- 대표적인 딥러닝 라이브러리
- 텐서플로우(Tensorflow) by Google
- 파이토치(PyTorch) by Facebook
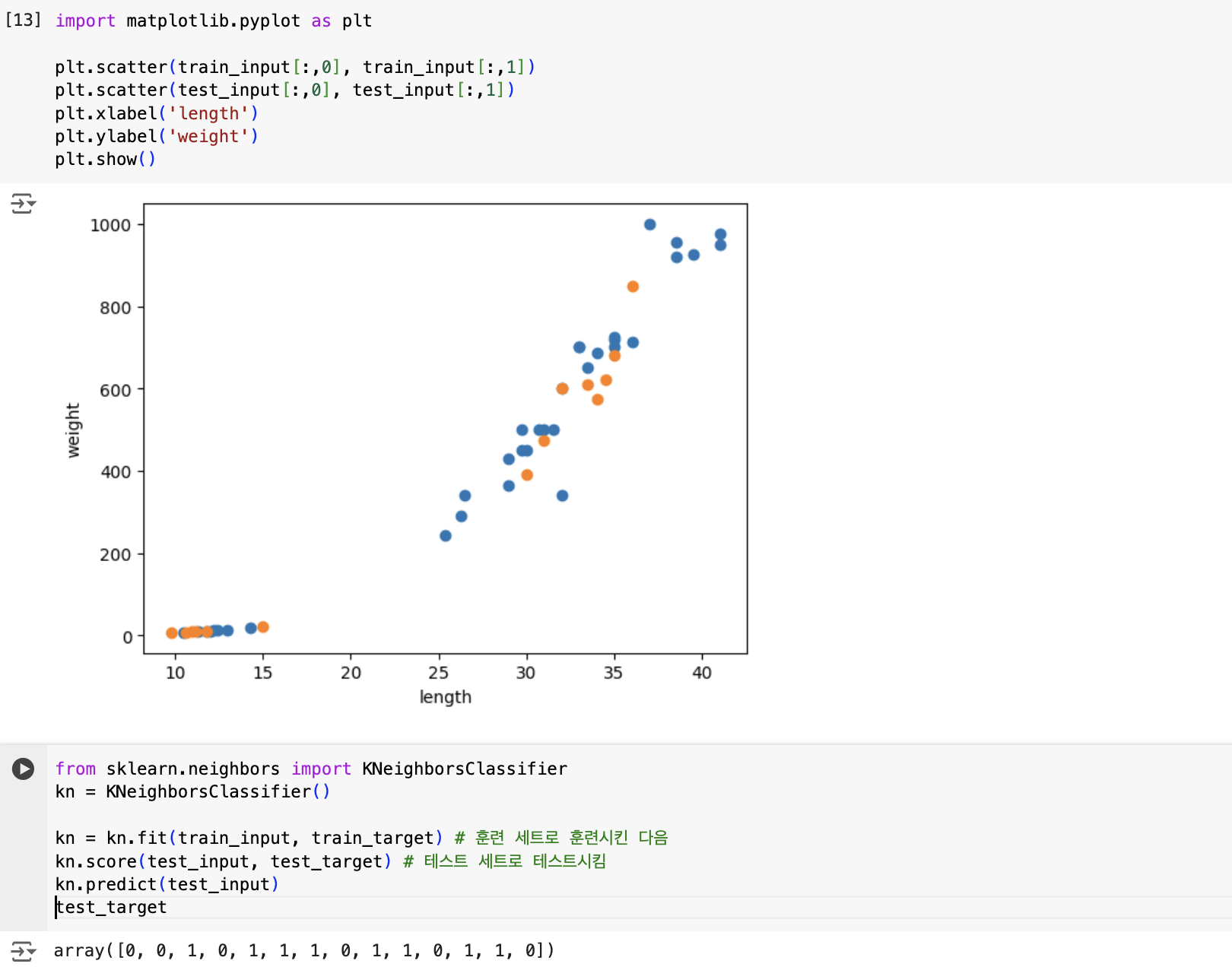
1-3 마켓과 머신러닝
<머신러닝에서 사용하는 기본 용어들>
특성(feature) ? 데이터의 특징 (like 생선의 길이, 무게)
산점도(scatter plot) ? x, y축으로 이뤄진 좌표계에 두 변수(x, y)의 관계를 표현하는 방법
맷플롯립(matplotlib) ? 과학계산용 그래프를 그리는 대표적인 파이썬 패키지
- scatter() : 산점도를 그리는 함수
- xlabel() : x축의 레이블
- ylabel() : y축의 레이블
- show() : 그래프를 화면에 출력해주는 함수
선형(linear)적 ? 산점도 그래프가 일직선에 가까운 형태로 나타나는 경우
훈련(training) ? 모델에 데이터를 전달하여 규칙을 학습하는 과정
- 사이킷런에서 fit() 메서드를 사용하여 훈련을 시킴
모델(model) ? 머신러닝 알고리즘을 구현한 프로그램
k-최근접 이웃 알고리즘(K-Nearest Neighbor) : 가장 가까운 이웃을 참고하여 정답을 예측하는 알고리즘, K-NN이라고도 부름
- 분류에 가장 기본적으로 사용되는 알고리즘
- 데이터를 모두 가지고 있다면, 이 알고리즘을 사용할 준비가 되었다는 뜻!
- 새로운 데이터를 예측할 때는, 가장 가까운 직선거리에 어떤 데이터가 있는지를 살피기만 하면 됨
- 단점 : 위의 특징으로 인해 데이터가 아주 많은 경우는 사용이 어려움
<사이킷런의 다양한 메서드들>
fit() : 사이킷런 모델을 훈련할 때 사용하는 메서드
predict() : 사이킷런 모델을 훈련하고 예측할 때 사용하는 메서드
- 출력값은 예측한 값이 나옴
score() : 훈련된 사이킷런 모델의 성능을 측정하는 메서드
- 출력값은 0-1로, 1에 가까울수록 정확도가 높다는 뜻
1주차 기본 숙제 : 코랩 실습 화면 캡처하기 (chap1-3)


Chapter 2 : 데이터 다루기
2-1 훈련 세트와 테스트 세트
지도 학습(supervised learning) ? 알고리즘이 정답을 맞히는 것을 학습함
- 지도 학습에는 데이터인 입력(input)과 정답인 타깃(target)으로 이루어진 훈련 데이터(training data)가 필요함
- 지도 학습 후 성능을 평가하기 위해서는, 다른 데이터를 준비하거나, 이미 준비된 데이터 중에서 일부를 떼어 내어 활용
- 테스트 세트(test set) : 평가에 사용하는 데이터
- 훈련 세트(training set) : 훈련에 사용하는 데이터
- 샘플링 편향(sampling bias) ? 훈련 세트와 테스트 세트에 샘플이 골고루 섞여있지 않을 때, 샘플링이 한쪽으로 치우치게 되는 현상
-> 테스트 세트와 훈련 세트에는 샘플을 골고루 섞어, 실행시켜야 함. 근데 이걸 어떻게 수행하냐? -> numpy 사용!


행 : 샘플
열 : 특성
알아두면 좋을 것 같아서 적어놓음
비지도 학습(supervised learning) ?
- 타깃 없이 입력 데이터만 사용함
- 데이터를 잘 파악하거나 변형하는 데 도움을 줌
1주차 기본 숙제 : 코랩 실습 화면 캡처하기 (chap 2-1)

1주차 추가 숙제 : Ch.02(02-1) 확인 문제 풀고, 풀이 과정 정리하기
Q1. 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은 무엇인가요?
A1. 지도 학습
풀이 : 알고리즘이 정답을 맞히는 것을 학습함, 비지도 학습과는 달리 타깃을 사용하는 것이 특징
Q2. 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상을 무엇이라고 부르나요?
A2. 샘플링 편향
풀이 : 샘플링 편향(sampling bias) ? 훈련 세트와 테스트 세트에 샘플이 골고루 섞여있지 않을 때, 샘플링이 한쪽으로 치우치게 되는 현상
-> 테스트 세트와 훈련 세트에는 샘플을 골고루 섞어, 실행시켜야 함.
Q3. 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
A3. 행 : 샘플, 열 : 특성
풀이 : numpy에 있는 shape를 사용하면 샘플 수와 특성 수를 출력하는데, 해당 값은 각각 행과 열임
2-2 데이터 전처리
데이터 전처리(data preprocessing) ? 특성값을 일정한 기준으로 맞춰 주는 작업
- 몇몇 알고리즘은 샘플 간의 거리에 영향을 많이 받음, 기준이 다르다면 값을 올바르게 예측할 수 없음
- 표준점수(standard score) (or z점수) : 대표적인 전처리 방법, 각 특성값이 0에서 표준편차의 몇 배만큼 떨어져 있는지를 나타냄
mean = np.mean(train_input, axis=0) # mean() : 평균을 계산하는 함수
std = np.std(train_input, axis=0) # std() : 표준편차를 계산하는 함수
print(mean, std)
train_scaled = (train_input - mean) / std # 표준점수로 변환, (원본 데이터 - 평균) / 표준편차
k-최근접 이웃은 주변의 샘플 중 다수인 클래스를 예측으로 사용함
KNeighborsClassifier 클래스는 주어진 샘플에서 가장 가까운 이웃을 찾아 주는 kneighbors() 메서드를 제공함
이 메서드는 이웃까지의 거리와 이웃 샘플의 인덱스를 반환, 기본값이 5이기에 5개의 이웃이 반환됨 (샘플 중 2개는 도미이고 3개는 빙어)
따라서 직관적으로는 도미가 가까워보여도 가까운 샘플 5개 중 빙어가 더 많으면 빙어로 예측하게 됨
import matplotlib.pyplot as plt
distances, indexes = kn.kneighbors([[25, 150]]) # 가까운 샘플 5개 가져옴
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^') # marker : 모양을 지정
plt.scatter(train_input[indexes, 0], train_input[indexes, 1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
그런데 kneighbors로 판단해서 나온 distances는 거리의 기준이 다름
x축은 범위가 좁고 y축은 범위가 넓기 때문에, y축에서 조금만 더 멀어지면 거리가 완전 멀어진 값으로 계산됨
-> 이것이 도미가 가까운 샘플에 못 들어간 이유!!!
=> 기준을 똑같이 설정해야함 !! -> xlim(), ylim()을 사용하여 범위를 맞춰야 함
스케일(scale) ? 특성의 값이 놓인 범위
import matplotlib.pyplot as plt
distances, indexes = kn.kneighbors([[25, 150]]) # 가까운 샘플 5개 가져옴
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^') # marker : 모양을 지정
plt.scatter(train_input[indexes, 0], train_input[indexes, 1], marker='D')
plt.xlim((0, 1000)) # x의 범위를 1000으로 맞춰줌
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
표준점수를 구하고, 이 데이터로 모델을 훈련시키면 됨!
new = ([25, 150] - mean) / std # 훈련 세트의 mean, std를 이용해서 변환함
plt.scatter(train_scaled[:,0], train_scaled[:,1]) # 표준점수로 변환한 train_scaled를 사용하여 산점도 그리기
plt.scatter(new[0], new[1], marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
1주차 기본 숙제 : 코랩 실습 화면 캡처하기 (chap 2-2)





1주차를 마치며,
처음 개념이라 그런가? 왤케 재밌지 난 정말 컴공이 맞는 듯 ㅎㅅㅎ
아직 완벽하게 이해가 되지 않은 부분이 있어서, 그 부분들은 구글링으로 내용을 더 채워보거나 그림을 그려서 이해해보려고 한다!
시작이 좋다!!! 제발 용두사미만 안되길 바라며~~!!
'혼공머신' 카테고리의 다른 글
| [혼공머신] 6주차 : ch7) 딥러닝을 시작합니다 (0) | 2024.08.18 |
|---|---|
| [혼공머신] 5주차 : ch6) 비지도 학습 (0) | 2024.08.11 |
| [혼공머신] 4주차 : ch5) 트리 알고리즘 (0) | 2024.07.28 |
| [혼공머신] 3주차 : ch4 (0) | 2024.07.21 |
| [혼공머신] 2주차 : ch3 (11) | 2024.07.14 |